Traffic Distribution Methods in Cloud Infrastructures – Airoserver
The rapid growth of the internet and the migration of commercial, educational, and entertainment services to the web have fundamentally transformed infrastructure engineering. In past decades, when a website experienced slowdowns, network administrators simply upgraded the CPU or increased the RAM of that single physical server. This approach, known as vertical scaling, has undeniable hardware limitations. Today, digital platforms face millions of concurrent users, and no supercomputer in the world can handle such a massive processing load alone. At this scale, scalability becomes a vital necessity, and the survival of a business depends on its ability to respond to countless requests.
Cloud architecture introduces load balancing to solve this problem. In this architecture, instead of relying on a centralized supercomputer, thousands of smaller servers work together in coordination. However, having hundreds of servers is not enough; the main challenge is how to distribute millions of incoming requests fairly, intelligently, and without creating bottlenecks among these servers. This is where traffic management and distribution systems come into play. These systems act as the orchestra conductor in cloud networks, ensuring that no server is overloaded beyond its capacity and no user experiences service downtime.
What is Traffic Distribution in the Cloud?
The concept of traffic distribution in cloud infrastructures refers to a set of software and hardware processes responsible for receiving incoming user traffic and distributing it across multiple servers or processing instances based on specific algorithms. This process begins the moment a user enters a website URL into their browser and continues until the response is fully received.
The ultimate goal of traffic distribution is to achieve the highest level of availability. In a standard cloud environment, systems must be fault-tolerant. This means the infrastructure must be engineered so that if one or more processing servers fail due to unexpected hardware or software issues, traffic is immediately redirected to healthy servers within milliseconds, without the end-user noticing any disruption or downtime. Understanding this mechanism requires a deep knowledge of the foundational tools that enable this intelligent distribution across different network layers.
What is a Load Balancer and How Does It Work?
A load balancer is the beating heart of the traffic distribution process in modern networks. This system acts as an intelligent interface between internet users and origin processing servers. When massive traffic surges toward a domain, it does not directly hit the database or application servers; instead, it first enters the load balancer. This tool monitors the real-time status of connected servers and decides which server should handle each request to maintain balance across the entire network. In professional cloud networks, these components are divided into hardware load balancers and software load balancers, distributing traffic across different layers of the standard OSI model.
Managing Traffic at Network Layer 4
Distribution at the fourth layer of the network is based on foundational transport protocols, namely TCP and UDP. At this level, the load balancer does not inspect the content of the user’s data packet; it does not care whether a user is uploading an image or logging into an account. The system simply routes packets to destination servers based on the source IP address and requested port. Since no processing or decryption of data content occurs at this layer, routing speed is exceptionally high, and latency is minimized. This layer is widely used for routing traffic to databases and gaming servers that require fast exchange of raw packets.
Managing Traffic at Network Layer 7
Layer 7, or the application layer, is the most intelligent part of traffic routing. At this layer, the load balancer fully understands high-level protocols such as HTTP and HTTPS. The system can read request headers, cookies, URL parameters, and even the message body to make decisions. For example, it can be configured so that if a user requests a path containing video, their traffic is directly routed to a cluster of dedicated media streaming servers, while text requests are sent to lighter web servers. The incredible flexibility of Layer 7 comes at the minor cost of millisecond-level processing overhead, but it remains indispensable for modern web services.
Traffic Distribution Algorithms in the Cloud
Deciding which server should host which request is not a random process. Traffic distribution systems use precise mathematical and logical formulas called routing algorithms. Selecting the correct algorithm directly impacts the overall performance of the platform, and a wrong choice can lead to paralyzing bottlenecks in the data center.
Round Robin Algorithm
The Round Robin algorithm is the simplest and one of the most stable load balancing methods. In this mechanism, requests are distributed sequentially and in a circular fashion among available servers. The first request goes to server one, the second to server two, and so on until the last server, after which the cycle restarts from the first server. The biggest advantage of this method is its simplicity and low processing overhead for decision-making. However, its main drawback is the lack of awareness regarding the current state of the servers. It does not know if a server is processing a heavy video task or sitting completely idle, which may overload a struggling server. This method is typically used in environments where all servers have identical hardware specifications and tasks are brief and uniform.
Least Connections Algorithm
Unlike the previous model, this algorithm operates intelligently. The Least Connections mechanism monitors the number of active sessions and open connections on each server in real time. When a new request arrives, the algorithm directs traffic to the server with the fewest active connections at that moment. The advantage of this approach is that it effectively prevents request accumulation on a specific server. If a server is handling a long-running process, new traffic is routed to less busy servers. This algorithm is the best choice for platforms such as chat rooms, live communication sockets (WebSockets), and systems where request processing times are highly variable.
Weighted Load Balancing Algorithm
In cloud infrastructures that expand over time, servers often consist of different hardware generations. Naturally, a server with a new-generation processor should not bear the same workload as an older one. In the Weighted algorithm, infrastructure administrators assign a numerical weight or coefficient to each server based on its processing power and memory capacity. The traffic distribution system uses these coefficients to allocate a larger share of traffic to more powerful servers and a smaller share to weaker ones. This ensures that all available resources in the data center are utilized with maximum efficiency and no hardware component remains idle.
IP Hash Algorithm
Many web applications require a user to remain connected to a single, consistent server throughout their session to preserve user sessions and shopping cart data. The IP Hash algorithm is designed precisely for this need. This system takes the user’s IP address and runs a mathematical hash function on it to generate a unique key. Based on this key, the user is mapped to the exact same server on every subsequent visit. The main disadvantage of this method is that if many users access the site from a shared corporate or office network (behind a single public IP), all their traffic will flood a single server, disrupting the load balancing equity in the cloud.
Geographic Routing Algorithm
Geographic routing is one of the most advanced forms of traffic distribution on a global scale. In this model, the cloud provider uses IP address databases to identify the physical location and country of the user, then routes their traffic to the nearest data center. The major benefit of this method is the drastic reduction in latency during data packet exchange. A user accessing an international site from Tokyo receives responses from Asian servers, while a user in London connects to European data centers. Implementing this algorithm requires an extensive network distributed across different continents.

The Role of Health Checks in Preventing Service Downtime
Distributing traffic without monitoring the health of destinations leads to infrastructure failure. Imagine a load balancer sending thousands of requests to a server whose operating system has halted due to out-of-memory errors or whose web service has crashed. In this scenario, all those users would encounter frustrating server errors. The concept of Health Monitoring acts as a strict supervisor within the cloud infrastructure to prevent such scenarios.
The health check mechanism is a process where the traffic distribution tool sends test signals to all underlying servers at regular intervals (such as every five seconds). This signal can check an open network port, send a simple ping, or request a specific text file from the web server. If a server fails to send a correct and timely response across multiple consecutive attempts, the system marks that server as Unhealthy. Automatically and instantly, the faulty server is removed from the traffic distribution cycle, and all new connections are redirected to healthy servers. This phenomenon, known as Failover, forms the foundation of self-healing infrastructures.
For instance, during a major online flash sale, if one of the database nodes stops responding due to high load, the health monitoring system immediately detects the failure and shifts traffic to backup database nodes. In another scenario, within an API infrastructure used by developers, if one microservice returns a 500 internal error, the distribution system isolates it, preventing the disruption from ruining the user experience of other connected applications.
How Auto Scaling Integrates with Traffic Distribution
One of the most remarkable concepts in cloud architecture is its ability to adapt to sudden and unpredictable changes. Distributing traffic among ten servers is effective only as long as the traffic does not exceed the capacity of those ten servers. If a successful marketing campaign causes site traffic to increase a hundredfold within minutes, even intelligent distribution cannot save the service from collapsing. This is where Auto Scaling technology steps in, combining with traffic distribution to create an elastic infrastructure.
Scaling in modern cloud architecture is primarily achieved through Horizontal Scaling, which means copying and adding new virtual machines to the circuit rather than upgrading existing ones. When the scaling system detects an increase in system load, it boots up new servers and instantly registers their addresses with the load balancer, allowing traffic distribution to include these fresh nodes. Once traffic subsides, the extra servers are automatically shut down and removed from the distribution cycle to minimize organizational costs.
Scaling Based on CPU Utilization
The most common method to trigger auto-scaling is using hardware metrics. Network administrators configure rules; for example, if the average CPU utilization across a server cluster exceeds 70% for two consecutive minutes, the system must immediately launch a new instance and connect it to the distribution cycle. This method is highly precise and effective for websites that handle heavy mathematical processing or dynamic content generation.
Scaling Based on Incoming Traffic Volume
In some application platforms, the bottleneck is not the processor but network bandwidth limitations and the sheer number of concurrent requests. In this model, the scaling system makes decisions based on the number of requests per second sent to the edge of the network. As soon as the network traffic volume reaches a critical threshold, new virtual machines enter the circuit, and the load balancer divides the network traffic load among them.
Scaling Based on Request Queue Length
In advanced software architectures that utilize message brokers like RabbitMQ or Kafka, user requests are placed in a processing queue instead of executing directly. The cloud system monitors how many messages are accumulating in the queue. If the queue length increases and current servers cannot process messages fast enough, the system launches new servers specifically dedicated to clearing the queue, preventing latency in background processes.

The Role of CDNs in Global Traffic Distribution
Balancing load within a single data center only solves half the problem. If all your powerful servers are located in a single data center in Germany, a user connecting from South America will always experience latency due to long physical distances and multiple router hops. Content Delivery Networks (CDNs) act as a powerful intermediate distribution layer to extend the concept of traffic distribution from a single server room to the entire planet. By deploying dozens of Edge Servers worldwide, these networks deliver data at the edge of the network closest to the user, instead of letting traffic hit the origin server directly.
What is Anycast Routing?
One of the most innovative technologies in global distribution networks is the Anycast mechanism. In traditional networks, each IP address belongs to a specific physical server in one location. In Anycast routing, a single shared IP address is assigned to dozens of servers across different countries. Global routing protocols (like BGP) naturally direct each user’s traffic to the server that requires the fewest network hops. With this method, millions of users worldwide query a single IP address, but their traffic is intelligently distributed across different nodes of the global network.
How Edge Computing Works
Beyond storing static files, edge computing platforms represent the next generation of processing load distribution. In this technology, lightweight software codes run directly on edge servers near users instead of running on central cloud servers. This allows processes like user authentication, real-time image optimization, and malicious traffic filtering to occur without involving the main servers, significantly reducing the incoming traffic load on the central data center.
Differences Between CDNs and Load Balancers
Although both tools participate in traffic distribution, their responsibilities differ. A content delivery network focuses primarily on caching static files such as images, JavaScript files, and videos at the edge of the network, preventing repetitive traffic from reaching the main server. Conversely, a load balancer sits within the main data center to fairly distribute dynamic and transactional traffic (such as database searches or order processing) that cannot be cached among the available server cluster. These two systems complement each other in a stable cloud architecture.
Traffic Distribution in Multi-Region Architecture
Large, critical organizations such as banks and international platforms cannot tie their business stability to a single cloud data center. Natural disasters, regional power outages, or macro-level failures can completely take a data center out of service. To achieve the highest level of disaster resilience, network architects use a Multi-Data Center structure where processing resources are distributed across multiple geographical zones and traffic is managed between these regions. This design forms the core of Disaster Recovery plans.
Active-Active Architecture Model
In this ambitious and complex architecture, multiple data centers in different regions worldwide are simultaneously active, accepting and responding to traffic requests. Traffic management tools at the DNS layer distribute users across these regions based on geographical location or data center capacity. The incomparable advantage of this structure is that if one data center is completely destroyed, traffic is managed by other active data centers in other continents without any disruption or data loss. However, real-time database synchronization across multiple active data centers remains a complex and expensive technical challenge. This service, often realized via GeoDNS, is one of the best solutions for achieving absolute stability in the web world.
Active-Passive Architecture Model
In this model, which is more cost-effective but slightly slower during failover, primary traffic is directed to only one data center (Active). A second data center (Passive) in another region remains on standby, continuously replicating data from the primary server but serving no user requests. In the event of a disaster that takes the primary data center offline, the traffic routing system detects the outage, updates the routes, and redirects traffic to the backup data center. This rerouting may take a few minutes, but it prevents total service destruction.
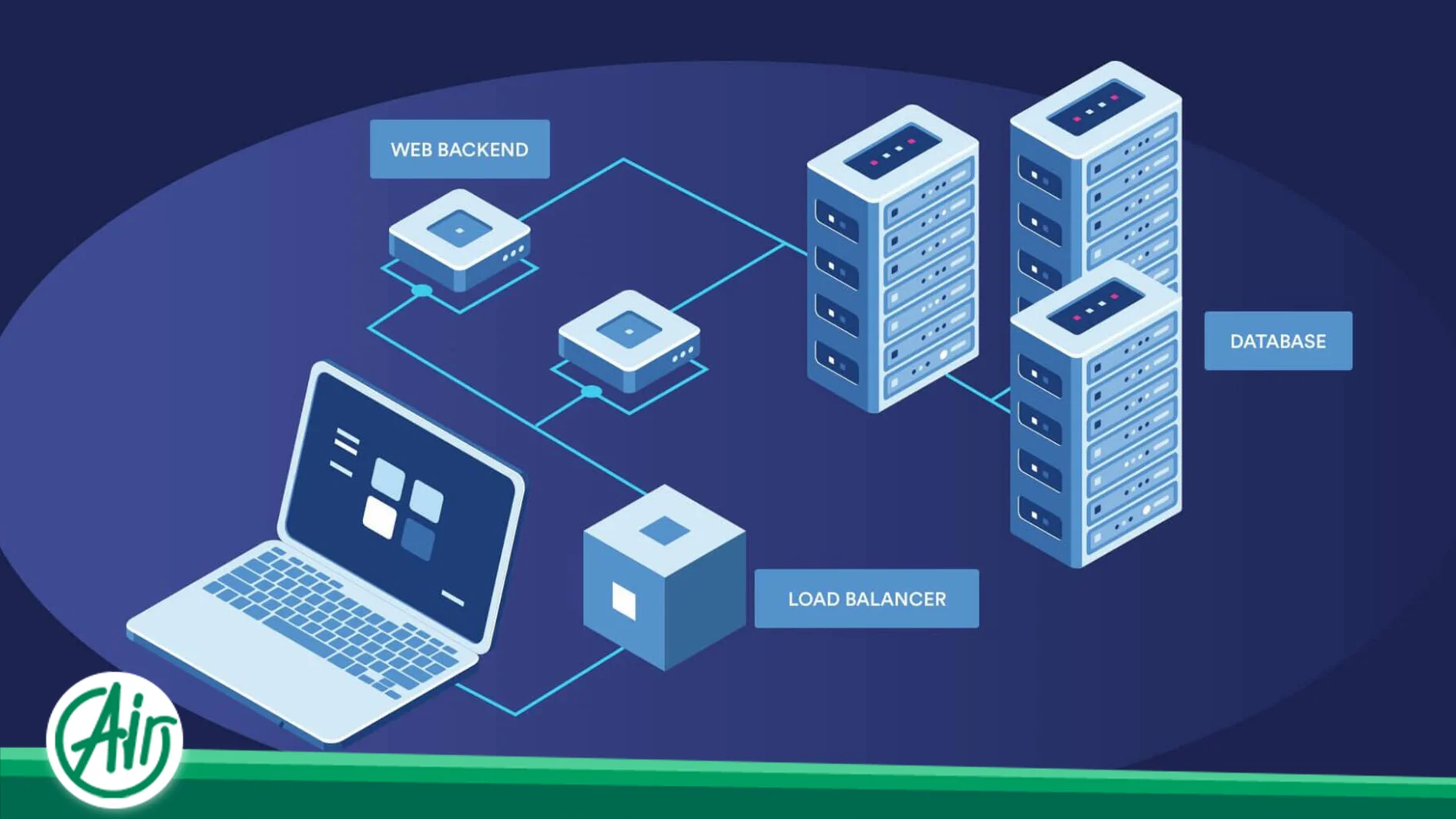
Challenges of Traffic Distribution in Cloud Infrastructure
Despite all the benefits, implementing and maintaining a distributed traffic structure presents numerous engineering challenges that system administrators must address:
-
Session Persistence: Maintaining user session states across multiple servers that constantly scale up and down is a significant hurdle for developers, often requiring fast intermediate databases like Redis to store sessions centrally.
-
Latency: Data packets passing through multiple routing layers, firewalls, network edges, and load balancers accumulate sequential delays, making path optimization a complex process.
-
Packet Loss: In internal network communications among hundreds of virtual machines, the probability of missing data packets and requiring retransmissions increases, heavily impacting database node communications.
-
DNS Propagation: When the traffic distribution system decides to take regional servers offline, propagating changes to DNS records globally can take time, occasionally routing traffic to decommissioned servers.
-
Bottlenecks: Sometimes the load balancer itself becomes a traffic bottleneck due to heavy decryption processing at Layer 7, requiring its own clustering and scaling mechanisms.
Differences in Traffic Distribution: Cloud vs. Traditional Servers
In traditional infrastructure, network architecture was typically built around a single, highly powerful centralized server. This architecture inherently possesses a Single Point of Failure; if the server’s power supply or processor fails, all services go down simultaneously. Conversely, modern cloud architectures are designed around distributed components and decentralized systems, creating exceptional resilience against hardware failures.
In older architectures, when traffic exceeds processing capacity, system administrators have no choice but to accept service degradation or perform physical hardware upgrades during scheduled maintenance windows. This upgrade process, which involves planned and lengthy downtime, does not exist in the modern cloud. The cloud environment, relying on resource flexibility blended with traffic routing systems, allows you to add or remove hundreds of processing nodes within minutes without a single second of downtime.
The Role of Kubernetes and Container Orchestration in Traffic Management
The emergence of container technology has shifted software architecture from monolithic structures toward microservices. In container orchestration platforms like Kubernetes, traffic distribution is executed in a much more dynamic and granular manner than in traditional infrastructures. Within a Kubernetes cluster, thousands of isolated software packages called Pods run independently, have short lifespans, and are constantly destroyed and replaced.
In this dynamic ecosystem, a concept called Service Discovery tracks the ever-changing addresses of containers in a central database. Incoming traffic from the outside world first reaches a boundary controller called an Ingress Controller. This controller inspects defined rules and request headers to route traffic to the appropriate service inside the cluster. The internal Kubernetes service then uses internal virtual network load balancing mechanisms to deliver the request directly to the target Pod. This multi-layered distribution provides exceptional stability for modern software.
Which Services Need Advanced Traffic Distribution the Most?
Not all websites require complex multi-region cloud architectures, nor do all businesses have the budget to implement these systems. However, certain technology sectors cannot survive without advanced traffic distribution systems due to the nature of their services.
High-Traffic E-Commerce Platforms
During sales seasons like Black Friday, e-commerce platform traffic increases thousands of times within seconds. Distributed routing of this heavy load is vital to prevent order processing and payment failures.
Video Streaming and Media Platforms
Delivering 4K video content to millions of concurrent users demands massive bandwidth. Utilizing edge cloud architecture and directing each user’s traffic to the nearest processing node is the only practical way to prevent constant buffering and video drops.
SaaS-Based Software Applications
Enterprise cloud applications hosting critical data and processes for other corporations have strict high-availability service level agreements (SLAs). Any disruption in a single server must not lead to downtime in an organization’s accounting or CRM services, making flawless load distribution an absolute prerequisite for trust.
Online Gaming Servers
In the world of game servers, millisecond-level delays (Ping) directly impact gameplay quality and determine user victory or defeat. Distributing traffic at Layer 4 of the network to find the least busy servers over the shortest physical path is a major infrastructure challenge for gaming.
API-Driven Architectures
Platforms providing banking infrastructure or identity verification for mobile applications face billions of machine-to-machine requests daily. Distributing and managing this massive request rate without powerful balancing systems will paralyze the entire software core within minutes.
AI Processing Infrastructures
Processing large language models and artificial intelligence tools requires immense graphical and computational power. This processing load cannot be handled by a single system; the distribution system divides the inference process into smaller segments and routes them across distributed clusters containing powerful GPUs.
Conclusion: Infrastructure Stability Relies on Intelligent Traffic Management
A cloud infrastructure without intelligent traffic distribution mechanisms would merely be a collection of raw, unreliable hardware components. Traffic management and routing form the glue that binds independent data center components into a cohesive, unified platform. As explored, using a single load balancer is only a small piece of the cloud architecture puzzle. To achieve high availability and absolute service guarantees, a chain of tools including edge content delivery networks, automated resource scaling, and continuous node health monitoring must align with precise routing algorithms. Distributed architecture is the great achievement of modern network engineering, turning flexibility and service continuity into a reality within today’s unpredictable web landscape.
Häufig gestellte Fragen
- What is the main difference between Layer 4 and Layer 7 load balancing?
Layer 4 load balancing operates at the transport layer (TCP/UDP) and routes traffic based on raw network data like IP addresses and ports without inspecting packet content, making it extremely fast. Layer 7 load balancing operates at the application layer (HTTP/HTTPS) and can inspect headers, cookies, and URL paths to make highly intelligent routing decisions at the expense of slight processing overhead.
- How does a load balancer know if a server has crashed?
Load balancers use a mechanism called health checks. They send automated requests or ping signals to the backend servers at regular intervals. If a server fails to respond correctly after a predetermined number of attempts, the load balancer marks it as unhealthy and stops routing user traffic to it until it recovers.
- Can Anycast routing replace a local load balancer?
No, they serve different purposes. Anycast routing works at the global network level to steer a user’s traffic to the nearest data center or edge location worldwide. Once the traffic arrives at that specific data center, a local load balancer is still required to distribute the incoming requests among the individual servers inside that facility.
- What happens to active user sessions during an auto-scaling event?
If new servers are added, the load balancer begins sending new requests to them. However, to prevent users from losing their login status or shopping carts (session disruption), developers use session persistence (sticky sessions) via the load balancer, or store session data in a centralized, high-speed database like Redis so any server can handle the request.
- Why is horizontal scaling preferred over vertical scaling in cloud environments?
Vertical scaling (adding more CPU/RAM to a single machine) has hard physical limits and introduces a single point of failure. Horizontal scaling (adding more server instances) allows for virtually infinite growth, cost optimization by turning servers off when traffic drops, and higher reliability since the failure of one instance does not bring down the entire system.
News
Berita Teknologi
Berita Olahraga
Sports news
sports
Motivation
football prediction
technology
Berita Technologi
Berita Terkini
Tempat Wisata
News Flash
Football
Gaming
Game News
Gamers
Jasa Artikel
Jasa Backlink
Agen234
Agen234
Agen234
Resep
Cek Ongkir Cargo
Download Film